Container Runtimes
One of the most frequent questions that they ask me about containers is to what extent they penalize performance. It is a very logical question because, in the end, the containers offer a certain level of isolation, they look like virtual machines … Something has to be penalized, right? In this post, I am going to talk about container runtimes, so that we understand a little more what it means to run a container.
Docker
It is almost inevitable to speak of Docker if we talk about containers, although in this case, it is to say that docker is not a container runtime. That may shock you since we usually install Docker to run containers, but things are not that simple. When Docker came out, it was a monolithic system that performed tasks that were really independent among them:
- Creation of images (docker build)
- Management of images and containers
- Sharing images (using records)
- Execution of containers
- An image format
OCI
OCI stands for Open Container Initiative and precisely its objective has been to define a unified image format. In OCI, among others, Docker, Google, and CoreOS participate. Later Docker “separated” his code to run containers and donated it to the OCI. From that came a library called:
runC
Now we are talking about a container runtime. runC is a small utility that is responsible for precisely that: run a container. In the background, runC is a wrapper that offers a CLI interface above libcontainer, the library that Docker used to run the containers. That library (libcontainer) is responsible for using the Linux kernel elements that support containers (such as namespaces and cgroups). Thanks to runC we can run containers directly, without going through the Docker engine. As you can see, indeed, it is a CLI:
Docker has already made a few versions (since 1.11) used internally by runC to run the containers.
containerd
Okay, we have on the one hand runC that is responsible for running containers. But one thing is to just run a container and another is to handle the entire life cycle of it, including the download of images, the use of volumes and appropriate networking. All of that is beyond the reach of runC and we need someone above that to do it. This someone is containerd. How can we define containerd? Well, we can say that containerd is a runtime of high level containers, as opposed to runC which is a runtime of low level containers . In fact, containerd uses runC to execute the containers and gives it all that additional functionality.
Remember that I said earlier that Docker 1.11+ used runC to run containers? Well, it does, but indirectly through containerd.
For Docker, having the container execution engine separate and its engine allows, among other things, to update the engine without having to stop containers.
rkt
When I spoke about OCI I commented that precisely if we standardized the image format, different tools from different manufacturers could perform different tasks. To run containers we have runC that comes from the “Docker side”. Well rkt is an equivalent to runC and containerd but that comes from the people of CoreOS. I say that it is equivalent to runC and containerd because rkt has low level and high level runtime characteristics. To this day rkt does not use the format defined by OCI if not its own (called ACI). For more information, you can check the OCI support roadmap.
Container isolation
Remember that in order for containers to be possible, it is necessary that the host OS supports them natively. Linux has been doing this for a long time through two Kernel features: namespaces and cgroups (control groups).
- namespaces: It is a characteristic of the Kernel that partitions the resources of the system so that different processes (or groups of processes) see different groups of resources. Networks, PIDs (process ids), mounts or IPCs are some of the resources that can exist in namespaces. This implies that a process can see a group of networks or PIDs that another process may not see.
- cgroups: Another Kernel feature that limits the use of system resources (CPU, disk, etc) to a group of processes.
Container isolation is constructed using namespaces and resource control using cgroups . There are no complicated virtualization, emulation or control techniques: it is based on resources offered by the OS’s own Kernel. That means that running a container is very light. Remember that the containers always share the Kernel: Kernel only has one.
Can we have containers with a higher level of isolation?
The Linux Kernel itself offers additional isolation mechanisms, such as seccomp : using seccomp, certain system calls (syscalls) can be forbidden from a defined set of rules. Then we have other tools, such as AppArmor (or also SELinux) that allow you to specify additional rules that the processes must comply with.
But depending on which environments we may need an isolation level between containers higher than that provided by the OS’s own Kernel. It is at this point where we can use a container execution environment that offers a sandbox. In the Linux world there are, at least, two alternatives that we can use: hypervisors or gVisor. In the Windows world we have Hyper-V.
Isolation using a hypervisor
In this case we have a model similar to that of a virtual machine: each container receives its own Kernel of the entire operating system. Thus, the container makes calls to its own Kernel (call it a guest kernel ) that through a VMM (Virtual Machine Monitor) communicates with the real kernel ( host kernel ). That is the general figure (we can perform certain optimizations through concrete paravirtualizations) where we obtain a great isolation in exchange for a cost in the performance (especially in the time of lifting the container). This level of isolation is often used in cloud environments using level 1 hypervisors (such as Xen), but we can also use level 2 hypervisors (such as KVM). A container runtime that uses hypervisors is runV .
This level of isolation is provided by Hyper-V in the Windows world. Indeed, in Windows we can run a container under Hyper-V which gives access to its own Kernel and all the isolation offered by a hypervisor.
Isolation using gVisor
gVisor is a relatively recent project from Google where they opt for another approach when isolating containers: gVisor “imitates” a guest kernel : intercepts calls to the container system and forwards them to the real Linux kernel. And, of course, before forwarding them, gVisor applies all kinds of rules and filters, to add the desired isolation. The isolation that gVisor offers in theory is between that offered by seccomp tools and that offered by hypervisors. In return, the cost in resources is much lower. gVisor offers its own container runtime called runsc that can be integrated with Docker and Kubernetes (through cri-o).
Container and Kubernetes Runtimes
Talking about container runtimes and Kubernetes is talking about CRI , the Container Runtime Interface .
Initially the support for different execution engines in Kubernetes was integrated directly into kubelet: thus both Docker and rkt were supported. That implied that adding support for future runtimes was very complex, since it required strong knowledge of the internal architecture of the kubelet. So, just as this post starts counting as Docker separated his code to uncouple it, this same path is going through Kubernetes. And the result is CRI.
Using CRI, container execution engines can be integrated independently without any need to modify kubelet (which is an element of the Kubernetes core). A (let’s call it that) CRI driver for a particular execution engine should not only allow to run containers but support everything that Kubernetes needs (metrics, networking, logging, etc). Of course, when CRI was defined, the first step was to remove the CRI drivers for the two execution engines that Kubernetes already supported: Docker and rkt.
So p. ex. using Docker CRI (aka dockershim), when we execute a container in k8s, the kubelet calls Docker-cri (using the API defined by CRI), which in turn calls Docker who as we have seen ends up using containerd to execute the container ( under runC).
Another option is to use a CRI driver for container and we jump directly to Docker, as you can see in this picture taken from the Kubernetes blog:
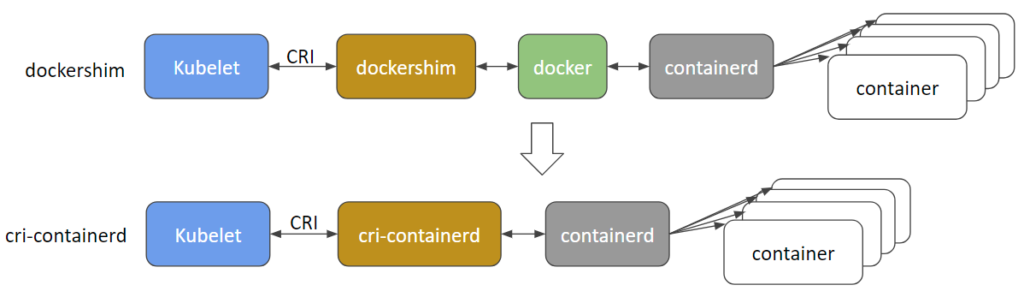
Currently, several CRI drivers are being developed:
- docker-cri (dockershim): That is already in GA
- rktlet: To use rkt under CRI
- cri-containerd: To use containerd directly
- frakti: To run containers under runV (using a hypervisor)
- cri-o: To use any runtime that is compatible with OCI
The important thing about these CRI drivers is that they “are not part of the core” of Kubernetes: you install the ones you need according to your needs.
Summary
When we talk about “running a container” we are talking about many things really. In this post, I tried to clarify a bit what happens when we run a container and what options we have to do it (at least today, because that progresses very fast).
Regards!